考古20年前的国产CPU:方舟一号和龙芯一号
20年前,准确地说是2001年7月和2002年9月,嵌入式CPU“方舟一号”和通用CPU“龙芯一号”相继发布,分别在嵌入式和通用CPU领域结束了我国无芯历史。方舟一号设计用途是网络通信处理器,因为无需软件生态,也不追求通用性能,所以自己设计了指令集。龙芯一号的目标是桌面计算机,软件生态很重要,各种各样的应用软件更需要CPU具有均衡的通用性能,于是采用了当时在高性能服务器中使用较多的MIPS III指令集。
这两款CPU在不同的领域代表着我国自主CPU的第一步,承载着一段历史,承载着发展自主CPU技术的希望。但我更感兴趣的是它们的技术特点和差异,想要弄明白为什么方舟一号分明诞生得更早,但结束“只能使用进口CPU制造计算的历史”的却是龙芯一号。人云亦云不是我的风格,我的疑惑只能自己解决。这两款CPU太老了,资料很难查找,但我还是成功收集到了足够的信息,终于弄明白了这个问题。
下面我先把它们的一些参数列一个表格,然后再细细说明它们的特点和差异。
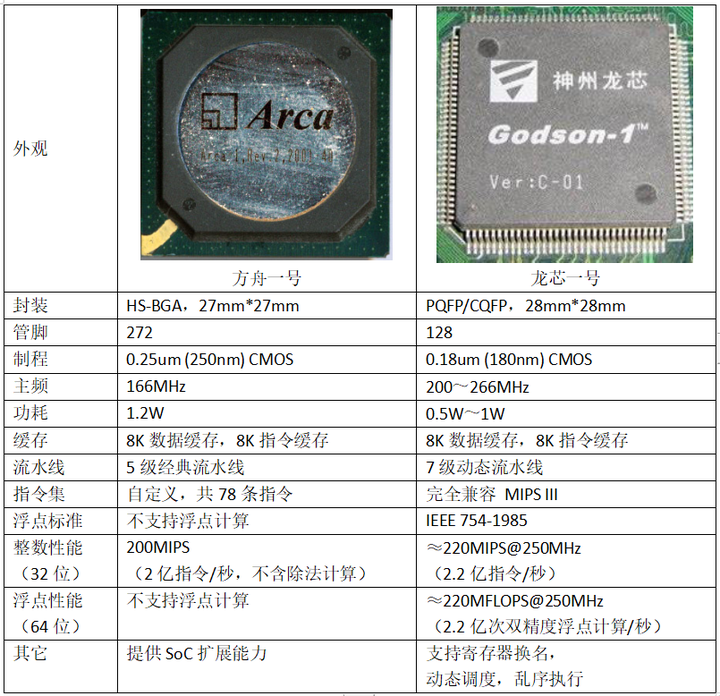
两者封装大小差不多,但方舟一号的管脚数量更多,这是因为它是嵌入式设计,许多的设备管理功能都集成在芯片内部,更多的引脚可以直联更多类型的的外部设备和低速总线。龙芯一号因为制程相对先进一些,并且作为通用CPU不需在芯片内部集成各种附加功能,频率更高反而功耗更低。缓存大小两者一样,功耗也差不多,整数性能看起来也差不多,那为什么仍然说方舟是嵌入式CPU,而龙芯是通用CPU呢?
两者的整数性能虽然看起来接近,但实际的评价标准却不相同。方舟一号是设计为处理网络数据的嵌入式CPU,要求低成本低功耗,因此设计十分简化,比如指令集中没有包含除法指令,只支持加、减、乘的整数计算,除法和余数计算都只能用软件方式处理。所以说方舟一号的200MIPS指标是不包含除法的,这在当时也是许多嵌入式CPU都有的特征。方舟一号与当时绝大多数的嵌入式CPU共有特征还包括不支持硬件浮点运算,以及不像通用CPU那样通过动态调度、乱序执行、分支预测等方式来提高程序的运行效率。
后来的方舟二号和一号相比,在设计上区别不大,主要还是通过使用更先进的工艺制程,改进物理设计来提高工作频率。二号的主频达到了400MHz,但指令集仍然只有78条指令。而龙芯一号则完整地实现了MIPS III的全部指令,在设计上也是以通用CPU为目标。MIPS架构(指令集)的资料比较多,不需要详细说明,方舟架构的资料很少,我也是偶然从一个网友那里得到了它的指令集参考手册。通过对方舟指令集手册的阅读,并与龙芯一号进行比较,我总算明白了方舟不适合作为通用CPU的原因。
首先是特权等级,方舟架构并没有像通用CPU那样进行特权指令和用户指令的区分,也就是说应用软件可以为所欲为,只有在软件完全可控的嵌入式环境中,才可以保证整个系统的安全性。方舟架构虽然分为用户模式和监督模式,但监督模式只是用于处理异常和中断,与安全无关。龙芯一号除了实现了MIPS-III中定义的特权等级之外,还额外地实现了抵御缓冲区溢出类攻击的硬件安全设计,整个计算机系统的安全具有较高的保障。
然后是指令集的设计,为了降低CPU的设计复杂度,减少晶体管数量,方舟架构总共只有78条指令。虽然远不如通用CPU指令集丰富,但与其它的嵌入式CPU相比则是同一水平。方舟架构也是继承了RISC思想的典型设计,指令字长32位,有32个通用寄存器,内存访问是Load/Store的模式,其它指令的操作数都来自寄存器和立即数,而不直接访问内存。下图是方舟指令集参考手册中的指令列表,从图中可以看到许多适用于嵌入式而不适用于通用CPU的指令设计。
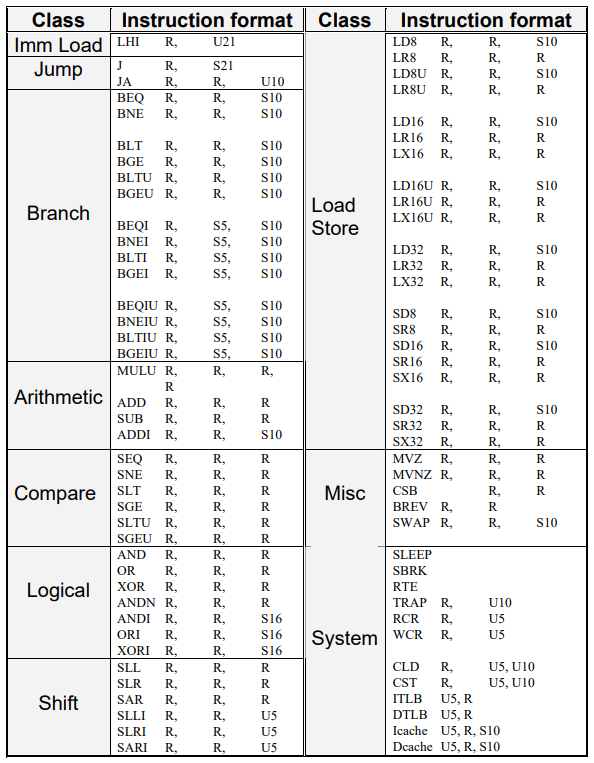
- 立即数(直接写在代码中的数字)加载只支持21bit的无符号数,而没有加载有符号立即数据的指令。有符号数只能先放在内存中,再用Load类指令加载到寄存器,对于有大量立即数参与的计算,运行效率偏低。
- 直接跳转指令支持两种寻址方式,J指令跳转目标地址由21bit有符号立即数直接指定,这种在代码中固化绝对地址的跳转方式,只在嵌入式应用中才会出现。JA指令的寄存器+偏移量寻址倒是通用处理器中常见的方式,但偏移量只支持10bit无符号数,偏移范围很小,只有4K(1024<<2)字节。10bit的范围是0~1023,仅1K字节大小,但由于指令字长32bit(4字节),指令会隐含地把立即数左移2bit,因此实际范围扩大了4倍。4K长度可以适用于简单的嵌入式程序,但桌面程序需要的跳转范围一般要大得多,如果要适应复杂的桌面应用程序,就需要接力跳转。
- Branch类是分支跳转指令,也就是根据大于、小于等各种条件跳转到不同的代码分支。但跳转的偏移范围是用10bit的有符号立即数表示的,有效范围是±2K字节(512<<2),对于桌面应用程序来说这个跳转偏移范围太小了。MIPS III的分支跳转范围是16bit有符号数,范围是±128K字节,对于20年前的应用程序还够用,到了现在就成了影响程序性能的因素之一。
- 方舟架构的整数运算指令只有4个,其中加法分为寄存器加寄存器和寄存器加立即数两条指令,乘法和减法各一条,没有支持立即数的格式。实际程序中有大量的使用固定数字参与计算的表达式,在方舟架构以及其它类似架构的CPU上,就需要从内存中把数字读入寄存器再进行计算,比常见的通用CPU要多花费一条指令。而且没有除法指令,所有的除法和余数计算都要使用软件方式来处理,比如最简单的软件除法就是用被除数减去除数,把结果再赋值给被除数,在循环中统计减了多少次之后结果为负数,次数减一就是商。虽然算法很简单,但完成这样一次循环至少需要十几条指令,循环多少次需要执行的指令数就翻多少倍,而硬件除法只需要一条指令。虽然可以优化软件除法的代码,但仍然会远远低于硬件指令的效率。在简单的嵌入式程序中这种效率是可以接受的,不过如果与通用CPU相比,即使80286这样古老的CPU,也是有硬件除法指令的。在当时,不只是方舟,还有许多同类的嵌入式CPU也是这样的设计。
- 缺少浮点指令,这也是当时各种嵌入式CPU的共同点。因为不支持基本的浮点加减乘除,那么更高级的三角函数、对数、指数等各种与浮点计算相关的指令也是不存在的。缺少硬件浮点计算的能力对于嵌入式CPU不是问题,无论是路由器、交换机这类网络通信设备,还是电子词典、学习机这样的消费产品,都不需要进行大量浮点计算,使用软件浮点就能满足要求。但在2000年之后,没有硬件浮点的CPU已经不可能用于通用计算设备,即使386都可以额外配置387浮点协处理器,486的满血版本已内置了浮点单元,何况当时已经进入了Pentium 4的时代,桌面环境中大量的图形图像计算都非常考验CPU浮点计算的能力。在Linux命令行下工作的专业软件虽然不需要软件界面,但在科研领域对浮点计算的性能要求却远高于普通的桌面软件,作为通用处理器的龙芯一号虽然有不弱的硬件浮点性能,但事实上也满足不了当时对CPU性能的要求,毕竟龙芯一号只有相当于Pentium 2的性能,与当时Intel最高性能CPU差距极大。
- 方舟架构的其它指令在当时也同样都只能适用于嵌入式应用场景,主要是指令的数量太少,有许多较复杂的计算必须分拆成多条指令来执行,无法高效地运行通用应用程序。只是单从指令集分析,我无法确切知道方舟一号与龙芯一号的性能差距。其实把它们俩放在一起对比性能是不公平的,因为方舟一号本身就是为嵌入式应用而设计,并不擅长通用计算,假如测试程序中有大量除法和浮点计算,或者逻辑比较复杂有大量的条件判断和分支跳转,方舟的弱势就会非常明显。
- 方舟一号除了在指令集方面不能承载通用应用,在CPU的设计上也尽量简化,比如龙芯一号中那些现代通用CPU的特征,方舟一号就没有。但方舟一号属于嵌入式CPU的大量特征也是龙芯一号没有的,比如SoC扩展能力、功耗管理单元、定时器单元、片上系统总线和设备总线等等,都表现出方舟一号是一款设计成熟的嵌入式CPU,能够满足当时国内对嵌入式CPU的大部分要求。
一年半之后的方舟二号也使用了0.18um的制程,通过更好的工艺和改进的设计把功耗降低了四分之三,也就是300mW的样子,频率则达到了400MHz,加上把指令缓存和数据缓存增加一倍,CPU整体性能估计应是方舟一号的2.5倍左右。这与方舟架构参考手册中提到的目标相符:“The instruction set was designed to allow a very small with very low power consumption, yet highperformance implementation. ”——该指令集的设计允许一个非常小、功耗非常低但性能很高的实现。只可惜方舟3号没有继续完成,方舟的领头人自己放弃了,没有坚持到底!!!

从资料中我明白了方舟系列CPU确实是专为嵌入式应用而设计,无法作为通用CPU使用。而龙芯一号无论是指令集还是结构设计,都是以通用CPU为目标,虽然性能只相当于Pentium 2,但确实能够适用于各种应用场景,运行任何应用程序都没有明显的短板。能够用来制造包括PC在内的通用计算设备,大概就是“通用”的本意。后来的龙芯二号性能达到了龙芯一号的3~5倍,虽然仍然与当时的主流CPU有很大差距,但在一些对性能要求不高的场合也有了成批量的使用。当前龙芯最新型号3A5000的性能已经踏进了主流CPU的门槛,并使用了自主设计的LoongArch架构(指令集),龙芯CPU的软件生态也在有序发展,终于坚持到了朝阳升起。

本页面的文字和图像允许在CC-BY-SA 3.0协议四和GNU自由文档许可证下修改和再使用。